What should one think of the 2026 DORA brochure?
The 2026 DORA Report on the ROI of AI-Assisted Software Development, or how to destroy the reputation of a respected research body in 60 pages.
On April 30th Google Cloud’s DORA team released its latest “report”.
I spent a decent amount of time reading through it and checking some of the referenced sources.
In today’s article, I’m offering my usual unfiltered and opinionated take on it.
As we go through the analysis, I hope the reason why I refer to it as a brochure, rather than a report, will become clear.
If it doesn’t, please reach out with your observations and comments.
Let’s start with a quick summary of the brochure.
The Core Message: AI as an Amplifier
The core message from the 2026 report, ambitiously titled The ROI of AI-assisted Software Development¹, is clearly spelt out in the executive summary:
Wait a second; this sounds familiar.
You might have read the 2025 report, called State of AI-assisted Software Development, whose executive summary read as follows:
The research reveals a critical truth: AI’s primary role in software development is that of an amplifier. It magnifies the strengths of high performing organizations and the dysfunctions of struggling ones. The greatest returns on AI investment come not from the tools themselves, but from a strategic focus on the underlying organizational system: the quality of the internal platform, the clarity of workflows, and the alignment of teams.
The previous report came out about 6 months ago2, and it’s important to note that it was written in close collaboration with IT Revolution as their premier research partner. IT Revolution is the company founded by Gene Kim, one of the two co-authors of the questionable Vibe Coding book, in which they both mentioned they had a clear goal to help DORA fix the 2024 anomaly, as they liked to refer to it.
 Sergio Visinoni
Sergio Visinoni
But back to the 2026 report: I’m only at page 3 and already wondering what new information it is bringing, compared to the previous one.
Things start becoming clearer, and somewhat interesting, in the following section of the executive summary.3
Quantify the ROI of AI Investments
The authors here introduce the real core idea of the brochure, because at this stage it’s no longer a report. The core claim is basically that investments in AI naturally follow a J-Curve path: a temporary productivity and stability dip before the trend reverts and gives you exponential growth.
The document is in fact a series of recommendations on how to sell the business case internally. And it’s obviously never questioning whether that should be the goal to pursue.
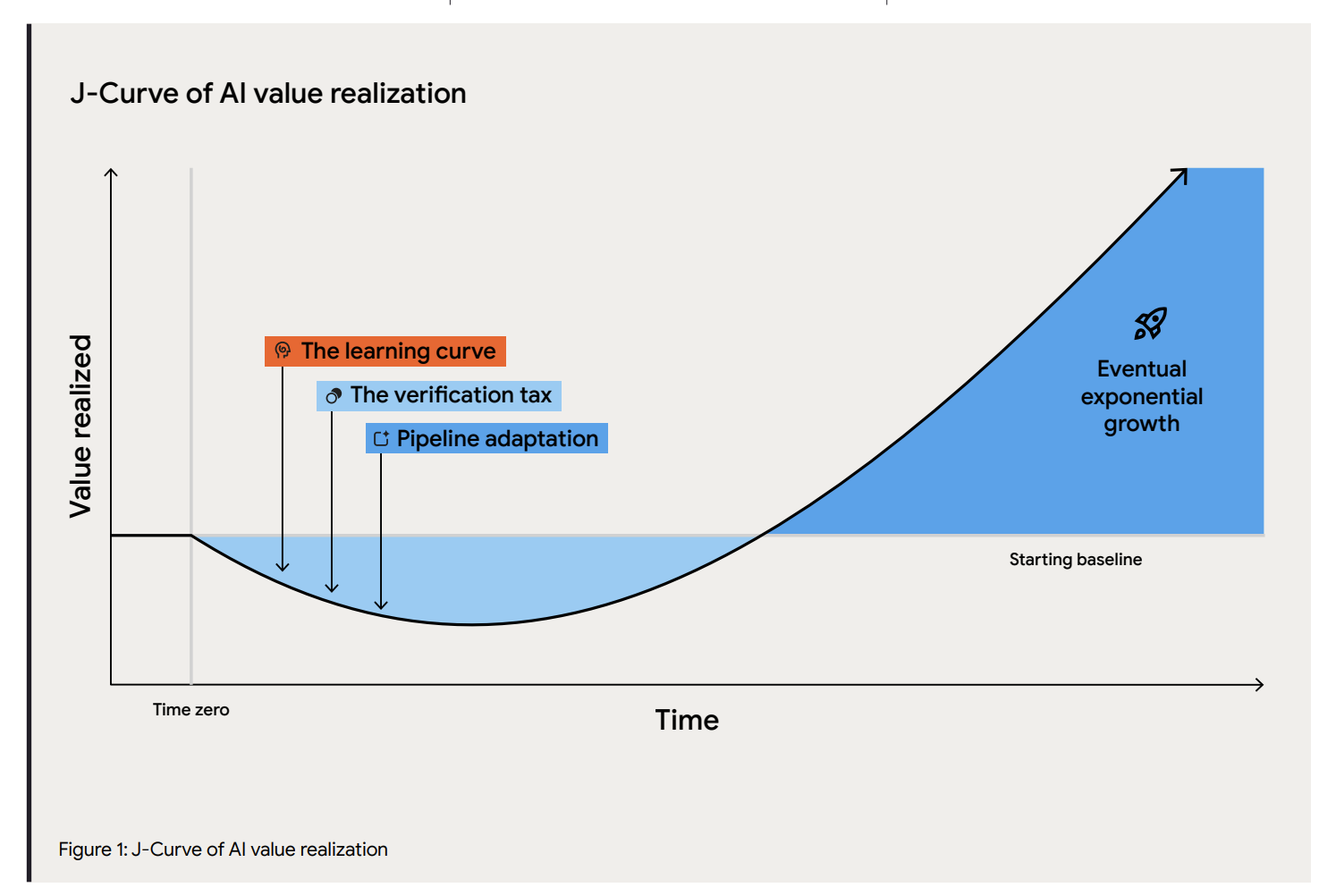
If you’re scratching your head at this point, you’re not alone.
While previous DORA reports, including the already mentioned 2025 issue, used to follow a genuinely rigorous research approach to help understand the current reality of what drives software delivery performance across the industry, the 2026 version is a set of recommendations mostly based on speculation.
Or, to use an analogy, if previous reports could be considered scientific books (though as far as I know, they have never been peer reviewed), the 2026 edition is the airport book equivalent.
Now, that sounds like a bold statement that I could get away with if I were a tech CEO, but since I’m not, I’ll do what normal humans do: provide arguments and evidence to support the claim.
#1: Relying on self-reported data
DORA studies have always been based on self-reported qualitative data. It’s something many teams don’t fully understand and often misleads them in their interpretation of the results, especially when they start implementing their own internal quantitative metrics.
While this has always been a caveat, when applied to the space of AI, things get worse.
All of the data represented on this chart is based on self-reported data.
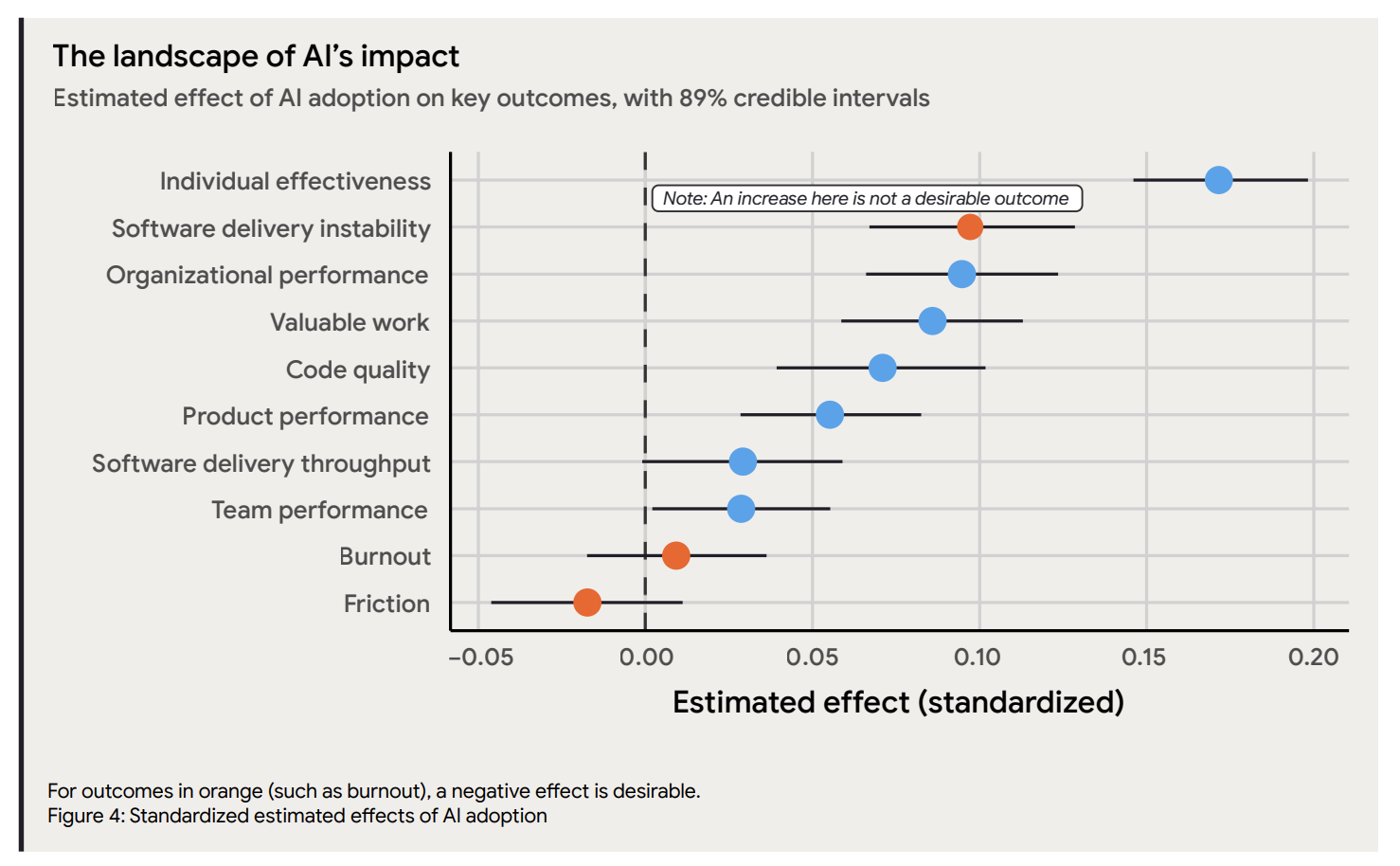
Now, the 2025 METR study4 highlighted something important, beyond the actual conclusions. People are extremely bad at estimating the improvements in individual productivity and tend to overstate them. It might be due to the fact that the AI discourse is loaded with propaganda and confirmation bias, which makes it significantly harder for anyone involved to maintain an objective view.
This becomes important when processing the results from the 2025 AI DORA report, as the most significant positive impact reported by practitioners is in the space of individual effectiveness. Such detail in itself does not invalidate any of the results, though the 2026 report could do a much better job at mentioning the important caveat.
#2: Core attribution flaw
This is my favourite part, and I think it’s the core flaw of the whole model.
Essentially, thanks to the work done on DORA over multiple years, culminating with the 2025 report, the researchers have identified a series of capabilities that operate as enablers for AI adoption. Remember, the core finding was that AI operates as an amplifier.
They summarise the value model in the following diagram.
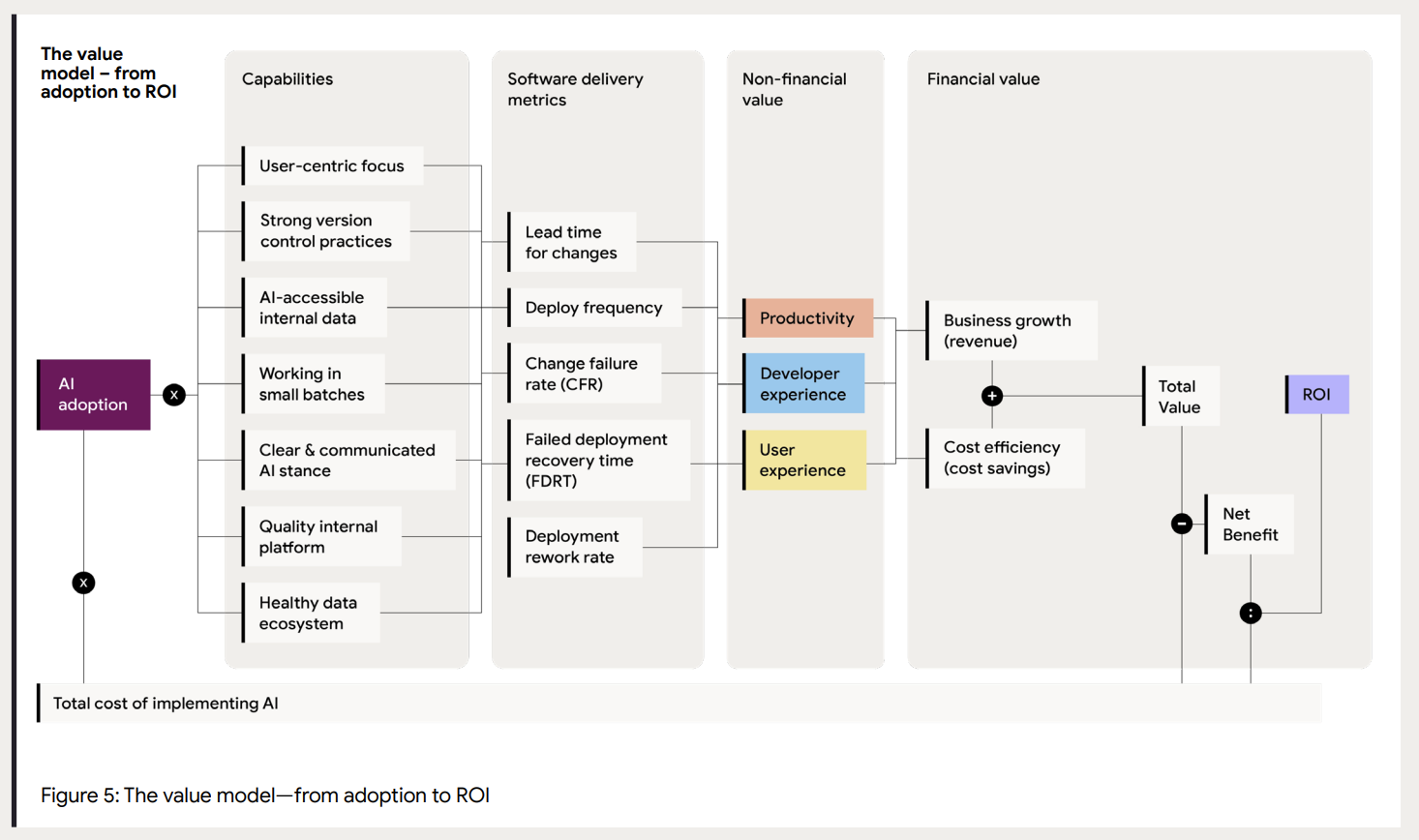
Now, here is the interesting part.
The whole point is that in order to get positive results from AI, you need to invest in underlying software engineering capabilities. These capabilities, with very few exceptions such as the AI-accessible internal data, are largely AI-agnostic. What I mean by that is that, as proven by the previous years of DORA findings, investing in those capabilities tends to lead to improved software delivery performances.
That was true before AI, and it seem to be just more true when you add AI to the mix.
So, while in the coverage of the ROI model is suggested (though largely glossed over) that the cost of these investments should be accounted for, all the benefits of the investment are simply attributed to AI adoption, without discounting the improvements generated by the enablers alone.
In other words, the ROI model doesn’t assess the isolated marginal benefit of putting AI on top of all these generic and proven improvements on the SDLC but mixes all of them together, effectively selling the idea that the results are directly caused by AI adoption, even if a significant portion of them are simply caused by better engineering practices.
All the benefits are bundled into the AI investment bucket, and that’s the fundamental attribution problem.
Now, for those of you with a penchant for wicked movies, as I was reading through this part of the report, I couldn’t help but think about the famous restaurant scene from Monty Python’s The Meaning of Life.
Careful, the images are honestly disturbing. You might want to skip the clip and read the description below. You have been warned.
Mr Creosote eats an outrageous amount of food. When he cedes to the insisting waiter and eats a mint at the end of the meal, he literally explodes. Attributing the explosion to the mint while ignoring everything he ingurgitated prior to it is exactly like attributing the ROI to AI alone while ignoring all the non-AI-specific investments made to support it.
#3: Weak supporting data
The report makes some other interesting claims that are glossed over. One of them immediately triggered my sceptical neurones:
Evidence from the Stanford Artificial Intelligence Index shows that raw inference costs for advanced models have plummeted remarkably, dropping by a factor of 280 between November 2022 and October 2024. Because the cost of querying models is approaching zero, the true financial burden of adoption has shifted to governance cost.
Wait, are we sure about that? Aren’t we seeing all AI companies increasing their prices instead? This is something I’ve been reporting on previously.
 Sergio Visinoni
Sergio Visinoni
Also, isn’t everyone constantly repeating that AI moves so fast that yesterday’s data is already stale and outdated? Then why look at the cost of inference between 2022 and 2024? Does it make sense to linearly extrapolate from a 2-year trend and assume it continues in today’s reality?
So I looked up the quoted article, looked into the section around inference cost, and found the following telling graph.
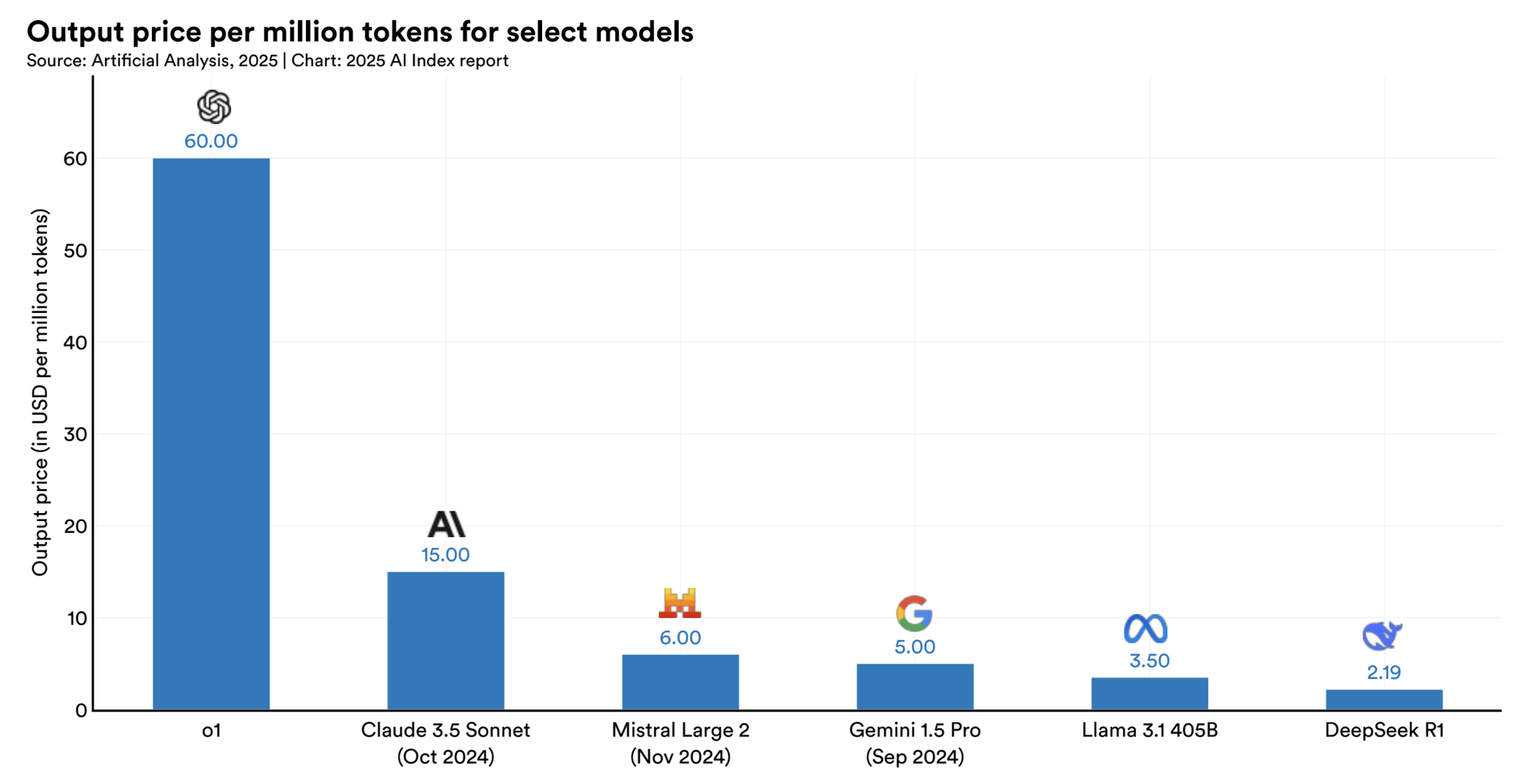
Who on earth is using any of these models for “serious” software development? Isn’t everyone telling the story that everything changed since Claude Code and then Sonnet/Opus 4.5 came out sometime last year?
So, let’s look at the price per million tokens for the models that are most popular these days:
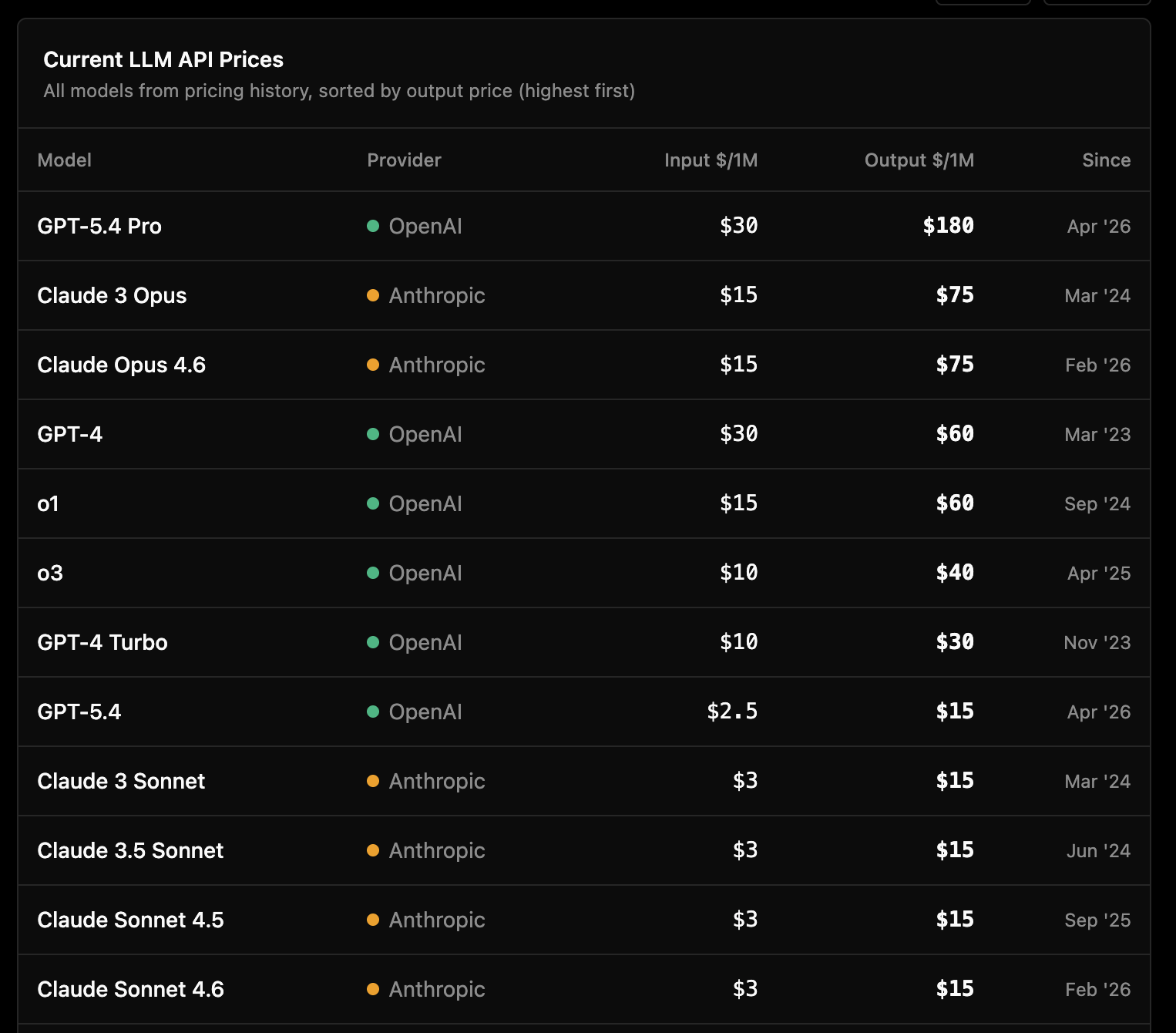
Essentially, the modern Sonnet 4.x models cost exactly the same as the 3.x generation from 2 years ago. The same goes for the Opus versions, and then you have GPT-5.4 costing an insane $180 per million tokens in output.
Add to this the fact that models are still largely subsidised, as their real cost is known to be significantly higher than what they’re priced for; the insane amount of investments in AI datacentre build-up we’ve witnessed in the past few years; and the emerging discomfort among CFOs as they see their AI bill skyrocketing, and the apparently innocuous statement that the cost of querying models is approaching zero suddenly deserves a lot more scrutiny and, above all, requires a lot more hard evidence.
Casually mentioning a study about models from more than two years ago, unfortunately, is not enough.
The second piece of weak data is the only mention of allegedly real ROI for existing companies. In a callout, the report states the following:
Google Cloud customers found an average of 727% return on their investment in Google Cloud AI in three years.
There are two problems with that statement:
It’s Google’s internal data. It’s available here, but as with any official company material, this should be treated as a marketing brochure.
While I went through the PDF quickly5, it’s clear that it focuses on a broad set of use cases, mostly in marketing and advertising, and on shipping GenAI-related features to end-users. It has nothing to do with using AI as part of the SDLC.
So I decided to simply ignore that data point, which only serves to muddy the water.
#4: Lousy financial model
In case this wasn’t enough, I found another important flaw with the report and, specifically, with the ROI calculation. The underlying financial model is overly simplistic. It is missing one key component, and that’s the concept of Net Present Value (NPV) and Discount Rate.
I am not a finance expert, but it doesn’t take a Nobel Prize in economics to recognise that the value of money decreases over time due to the effects of inflation.
NPV is the standard approach to calculate the future ROI of an investment that takes into account inflation. For that, the concept of discount rate is used, which can be defined as follows:
The sophisticated ROI model suggested by the DORA folks completely ignores it and simply treats future money as having the exact same value as present money. In case it wasn’t clear, that makes the ROI calculation look significantly better than it actually is.
I don’t know why they decided to not consider it, but its omission in my view undermines the credibility of the whole ROI model, which is in theory the core element of the entire document.
And I won’t even get into the details of the sample scenario provided, as it seems to be clearly designed to make it look good with an impressive 7 months’ payback time. That might be the reason why they omitted the discount rate, as they expect a payback time too short for that to have any meaningful value?
Though, a company that makes $100m in revenues with 500 FTEs in the technical staff alone and ships 50 “features”7 per year might have bigger problems to focus on than AI adoption.
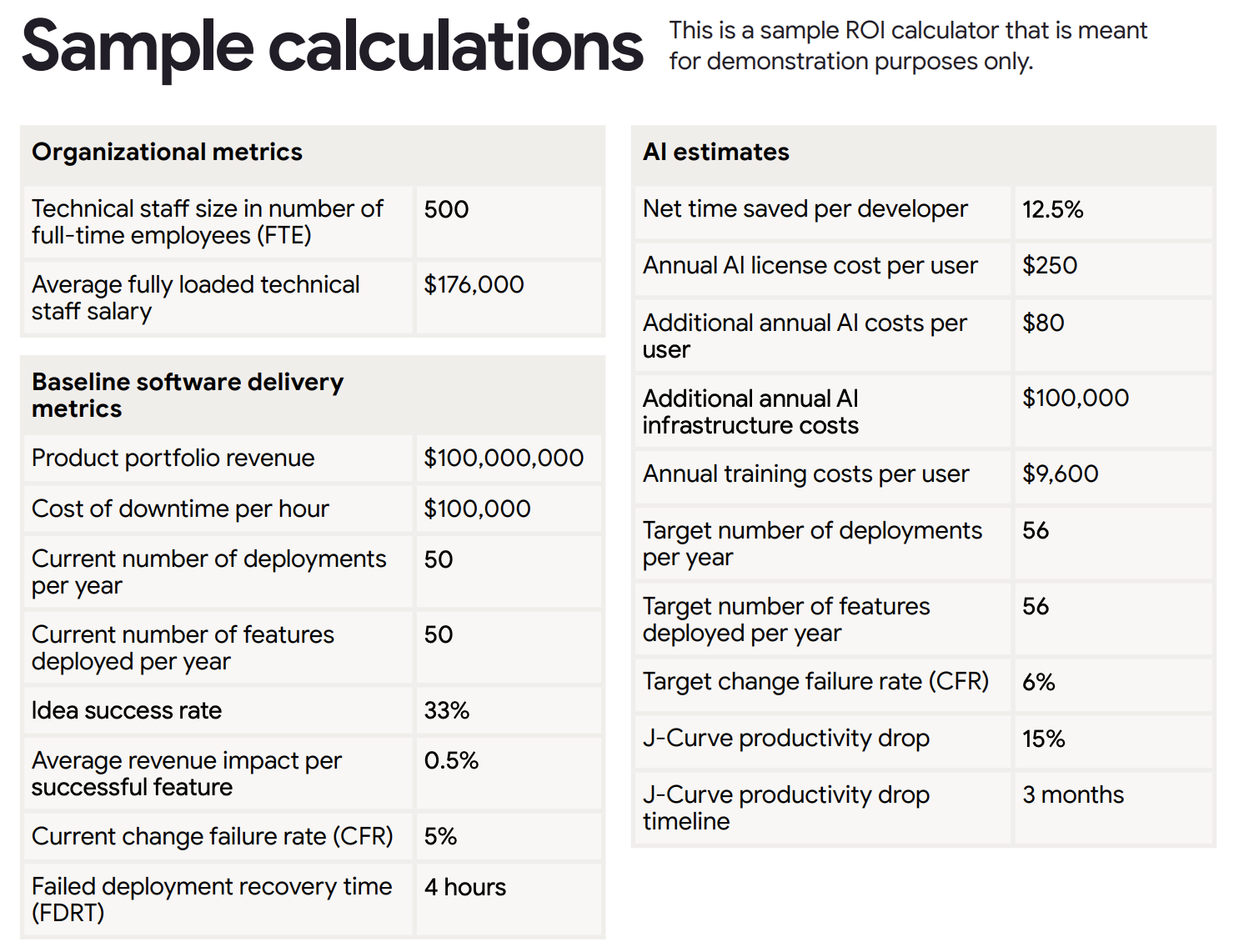
If a CTO needs to spend $5 million in AI to go from 50 to 56 features deployed per year, with a team of 500 engineers, I think they should have a serious employability problem.
Just saying.
Conclusions: A Brochure, not a Report
I’m sad to admit that DORA is no longer what it used to be. Unless this 2026 report becomes the real DORA anomaly and the team gets back on track with serious research with the next issue, I’m afraid 2026 might mark the beginning of the enshittification journey for what used to be a reputable body of research in the software delivery space.
Once you realise the depth of the gap that exists between all previous reports and this most recent brochure, you begin to pay more attention to the small details. Like the many calls to action, inviting leaders to reach out to Google Cloud and engage with their consulting services.

So, while I generally recommend people read articles, books, and reports, this is one of those rare (but increasing) cases where I discourage you to waste any time reading it.
Unless, of course, your main goal is to sell a fragile business case to your CFO and spend even more money engaging with Google’s service than you are doing today.
I find it impressive how methodical the authors are in defining every acronym, even AI… unfortunately they seem to gloss over more fundamental aspects of serious scientific reporting. More on it later. ↩
I tried to find the exact publication date, but surprisingly (and annoyingly) enough, it’s not mentioned in the PDF document nor on the corresponding lead magnet page. The PDF metadata, though, seems to indicate 2025-10-15 as the publication date. ↩
As an aside, I’m increasingly annoyed with the entire concept of an executive summary, as it implies the idea that executives should not “waste” their time reading through the details. I disagree, and today more than ever I believe executives should spend time reading through the details. Shallowness is another plague that AI seems to be amplifying. ↩
They did publish a 2026 follow-up experiment, which showed a speedup in the range of 4%-18%, but it should be considered largely inconclusive. As METR says literally, “However, the true speedup could be much higher among the developers and tasks which are selected out of the experiment. Some developers self-report very high speedups, though as we documented in our earlier study those estimates can be quite unreliable.“ ↩
Yes, because honestly, I’m not into marketing-material porn. ↩
Source PropertyMetrics. ↩
Let's not even engage on the value of counting features, as I need to wrap up this article eventually. ↩

Comments ()